Speech Compression via Discrete-Frequency Quantization
Introduction
The goal of this project was to attempt a new method of speech compression based on dividing an audio signal into discrete frequencies. The inspiration for this approach originates in the method used to transmit audio signals to a cochlear implant. The broader research motivations involved probing the question as to how much information was necessary in order for speech to be comprehensible. The project was designed as part of a National Science Foundation funded Research Experiences for Undergraduates program in Computational Science. The goal in that regard was to have a project that would help the undergraduate participants hone their skills at programming in Python.
Background
From an information theory point of view, human speech is very redundant. In other words there is much more information than necessary in speech to convey a message successfully. The same redundancy is present in written text. The show "Wheel of Fortune" relies on the fact that redundancy allows players to solve the phrase with only partial information showing. One of the motivations for this research project was to explore the limits on how little information was necessary for the content of a spoken sentence to be understood. A second motivation was to take a unique and different appraoch to speech compression. The standard methods of compressing speech typically use a vocal model to extract vocal tract excitation parameters that describe the pitch, loudness, and whether the sounds are voiced or unvoiced. This method began as a technique called linear predictive coding (LPC). Most modern speech compression algorithms (such as GSM-like algorithms used in apps such as FaceTime) are based on enhanced versions of LPC.
The approach taken in this project is very unlike other speech compression methods. It is inspired by the technique used to process sound for transmission to a cochlear implant device. The implant has a series of electrodes spaced along the basilar membrane located in the cochlea which is the spiral structure in the inner ear. Each electrode excites a single section of the basilar membrane corresponding to a single frequency. To convey sound signals to the electrodes of the cochlear implant involves breaking each time slice of the incoming sound into frequency bands centered around the frequencies corresponding to the position of the electrodes implanted in the basilar membrane. The total amplitude of the sound in each band determines the strength of the electrical signal sent to the appropriate electrode of the cochlear implant device. This explanation is a simplified version of how cochlear implants operate. The implant only approximates regular hearing; nonetheless, these devices have been enormously successful in addressing patients with profound deafness.
In this work we use the same approach as described above. However, we get wide latitude to choose the number of frequencies and their spacing. We hypothesized that such freedom would allow us to accurately reconstruct speech signals. The work was still ongoing when the project ended; however, as you can hear from the examples below, the quality of the recreated sound is less than ideal. As described below we tried many different approaches. In terms of the frequencies used, we tried evenly spaced and log spaced frequencies, frequencies that corresponded to the vowel formant structure, and even frequencies that corresponded to musical notes and chords. We jokingly refer to that last attempt as the T-Pain method (FYI, T-Pain is a rapper noted for using Auto-Tune pitch correction with extreme settings to get a signature vocal sound).
Algorithm Outline
There are three mains steps in creating and recreating a compressed file.
1. Split the Audio Signal into Small Time Windows
The audio file is separated into smaller time windows, usually 0.01 seconds in length. The windows can be overlapping or non-overlapping but choosing to overlap doubles the amount of data sent between devices. Theoretically, overlapping would provide a smoother transition between the windows and more accurately represent speech. Each individual window is applied a bell-shaped filter to smooth the cutoffs and prevent spikes during recreation. The common filter is called the Hann Window.
2. Find the Spectral Content of each Window using Fourier Transforms
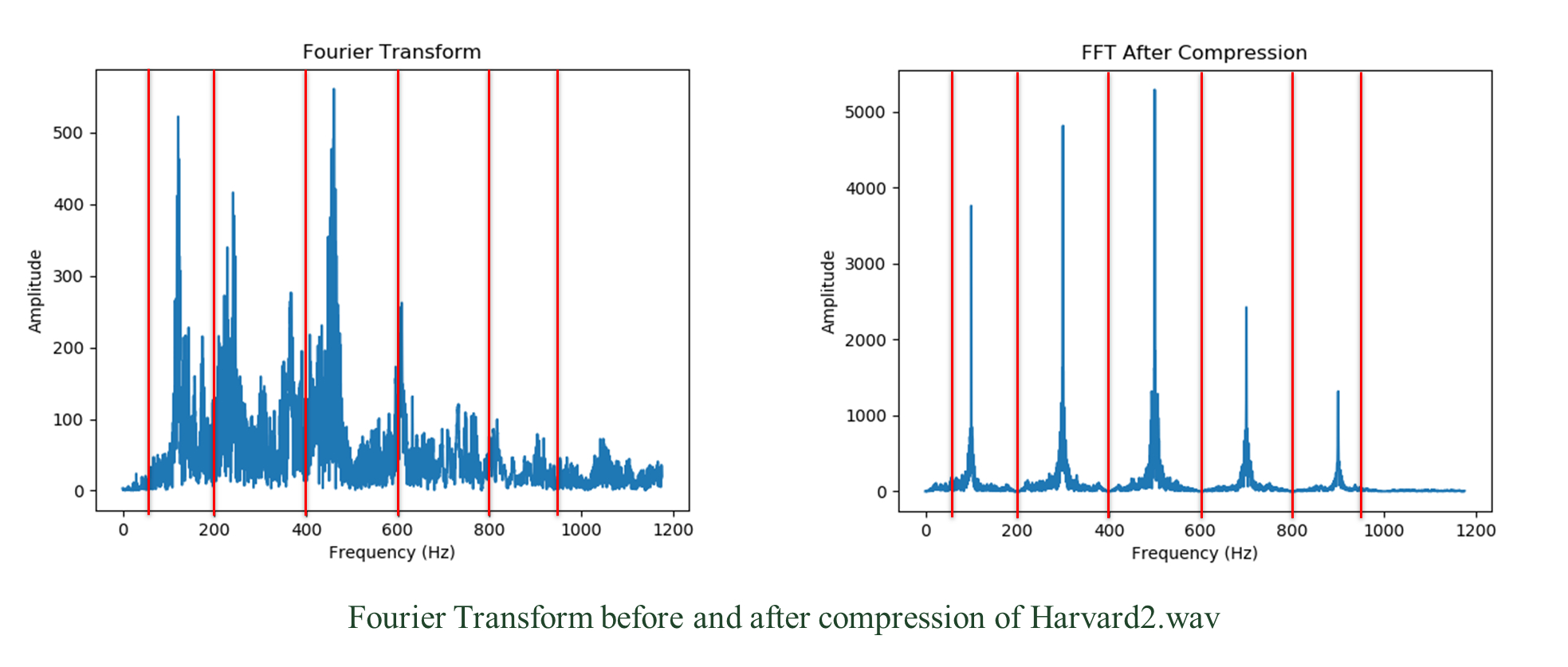
Specific frequencies are chosen by the user initially. Two frequency vectors instruct the code on separating and summing the Fourier Transforms of the individual windows. Ftest is a vector that provides the ranges of indices that will be separated in the Fourier Transform. Fcent contains frequencies within these ranges that will be the emphasized frequencies in the recreation of the audio file. For a Fourier Transform of an individual window, all amplitudes between Ftest[n] and Ftest[n+1] are summed together and put into the Fcent[n] row for that window’s column. In the data matrix, each column corresponds to a window of time, and each row corresponds to an Fcent frequency value.
3. Recreate the Compressed Signal
During recreation, a new audio vector is initialized and filled with information from the data matrix. Each window of the new vector is layered with sine waves of the amplitudes and frequencies from the data matrix. Amplitude is found from the data matrix, frequency is the value in Fcent, and time is the sample range in the new audio vector for where this frequency’s amplitude occurs using the relation: (2).
An example of Fcent and Ftest vector values may be Fcent = [100, 300, 500, 700, 900] and Ftest = [50, 200, 400, 600, 800, 950] where the first and last values of Ftest are +/- 50 Hz from the first and last values of Fcent, and the other Ftest values are in between the adjacent values from Fcent. Notice how the amplitude axis is significantly larger after compression. This is due to summing many frequencies together and only representing five frequencies in the compressed audio file.
Examples
Here are two different compression versions of the same original sentence. The first compressed file used white noise bands in recreating the signal. The result is not good unless you're trying for some sort of Gollum effect. The second uses 20 evenly spaced frequencies between 100 Hz and 4000 Hz. Listen to the compressed and see if you can understand what is being said before listening to the original.
- Compression with a mix of white noise and discrete frequencies
- Compression with 20 evenly spaced frequencies
- Original Sentence
You can hear a comparison of compressed and original sound files in this online "test" of comprehension. Click here for the test.
Who the heck is T-Pain?
Well, we addressed who T-Pain is in the link above. Check out YouTube if you want to hear his music. We make our T-Pain-like sounds by choosing frequencies corresponding to musical notes as the discrete set of frequencies to compress and recreate a speech signal. This choice results in a weird musical cast to the recreated speech. We feel sure this method will find application in some future rap or electronica musical creation. Well, maybe that's a little optimistic. Nonetheless, here are some audio examples.
- A very Southern Example, Original File
- Compressed in a musical way:
Executable Download
The program was written in Python. However, as most folks are not Python ready on their computers we created an executable version for both the regular compression program and for the musical Auto-Tune/T-Pain version. These are only set up to run on Windows (sorry, mac and Linux users). In addition, modern antivirus and malware detection programs often don't like executable files without "certificates" from Microsoft. As we are poor strugglings academics we don't have the wherewithall to pursue that option. On my system at home the program ran once successfully and then disappeared into some quarantine hole where AVG would not let me access it. Bottom line: you're on your own; we take no responsibility. The downloads come with instructions as to how to run the programs. Finally, if you have Python and want the original code we can send it along--click the contact link to get in touch with Dr. Robertson.
- Speech Compression Executable
- Speech Compression Program Instructions
- Guide about frequency options for the Speech Compression Program
- Musical Note Compression Executable Program
- Musical Note Compression Instructions
The Summer 2019 REU team
The participants in the Summer 2019 REU working with me (Dr. William Robertson) at Middle Tennessee State University (MTSU), Murfreesboro, TN are pictured below. From left to right, Dr. Robertson (needs a haircut), Colleen Olson (University of Wisconsin Eau-Claire), Austin Wassenberg (Carroll College), Alex Kaszynski (Colorado State University).

Contact
If you are interested in more information please feel free to contact Dr. William Robertson. We posted the executable because it is easier than trying to walk folks through the process of installing Python and all the required modules. However, if you are Python enthusiast we would be willing to send the source code subject to the MIT Open Source copyright license.
Send me an email at wroberts@mtsu.edu
Contact Information
Dr. W. M. Robertson
MTSU Box X-116
Murfreesboro, TN 37132
Ph. (615) 898-5837

